How to Find and Remove Duplicates in BODS Using gen_row_num_by_group() Function
By Imran, Mohammad January 24, 2022 under BODS
If you're concerned that your source data may contain duplicate records and you're unsure which rows are affected, there's no need to worry. BODS offers a special feature to easily identify duplicate records using the ranking method. In this post, I will guide you step by step on how to find and remove duplicates using an example. I will be using the built-in function called gen_row_num_by_group().
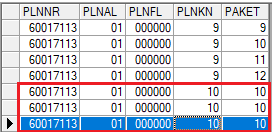
Source Data
In the example below, the last three rows are duplicate records. You want to identify them so they can be removed from the dataset.
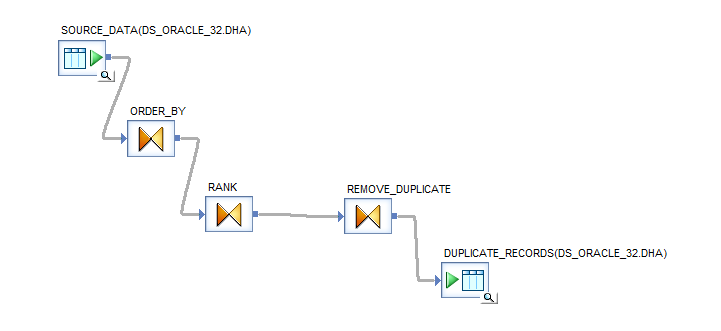
Query Design
Let's build a query in BODS. In the design shown below, an Order By query is used to sort the records in ascending or descending order. This sorting is important because when the gen_row_num_by_group() function is executed, it checks if the next row is the same as the previous one. If it is, the function identifies it as a duplicate and assigns a row number of 2 or higher.
If you do not apply the Order By clause, the records will not be sorted. As a result, the function may compare unrelated rows, and the control will not treat duplicates correctly. In such cases, even duplicate records might be assigned a row number of 1, which prevents proper identification and removal.
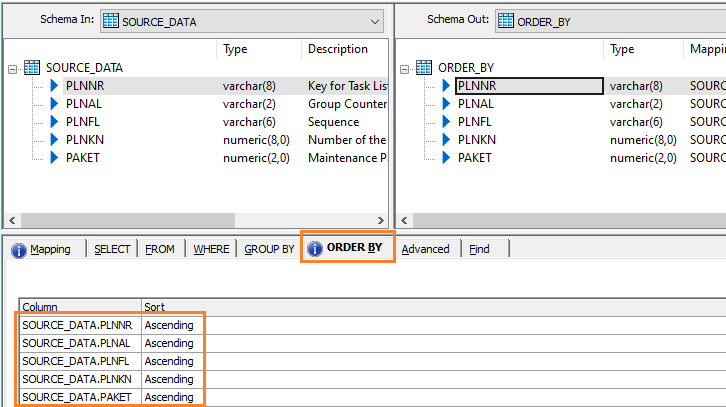
ORDER BY Transform
In the example below, I have included all the fields in the ORDER BY tab. The combination of these fields determines which records are considered duplicates.
RANK Transform
In the example below, the gen_row_num_by_group() function is used to assign a ranking to duplicate records. Non-duplicate records are assigned a value of 1, while duplicate records are given the next number based on their occurrence.
You should pass all the fields that define a duplicate record into the gen_row_num_by_group() function. In the example below, five fields contribute to identifying duplicates, so those five fields are passed into the function. If only one field determines duplication in your case, then pass just that one field.
However, make sure that the field(s) you pass to the function are already sorted in the previous query using an ORDER BY transform, to ensure accurate ranking.
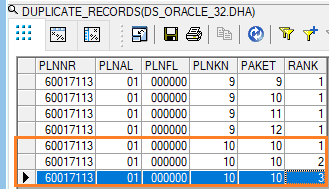
Output
In the example below, the last three rows are identified as duplicates and assigned ranks based on their occurrence. To remove the duplicates, you can retain only the rows with a rank of 1, and skip the others.
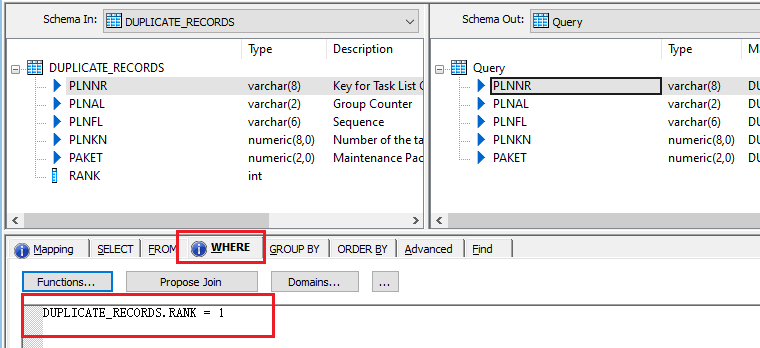
Removing Duplicates
In the example below, I have applied a WHERE clause in the next Query Transform. This ensures that only the records with a rank of 1 are passed forward, effectively removing the duplicates.
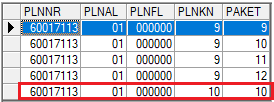
Duplicates Removed
In the example below, you can see that the last two rows, which were previously identified as duplicates, have been removed.
Conclusion
Although I have covered the key aspects of removing duplicates using the ranking method, feel free to reach out if you need further assistance on this or any other data migration topic.